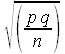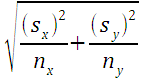Former Nike
shoe designer Andrew Estey felt that a more environmentally friendly running shoe could be
produced. The current design of running shoes use a lot of petrochemical resources and energy.
Andrew was sure there was a better way, starting with a simpler design, recycled materials, and
organic inputs such as bamboo fiber uppers. Andrew formed his own company,
Environmentally Neutral Design (END) and eventually released the
END Stumptown running shoe.
Being simpler, the Stumptown is lighter than the typical sort of shoes I have been running in for
over thirty years. Shoes like my Mizuno Wave Renegade IVs are 915 grams for the pair, while the Stumptowns are
only 665 grams for the pair. I began running in the END Stumptown shoes in March and I feel faster when I
run in them.
This examination uses speed data I have been gathering in the END Stumptown shoes.
In the first section of the examination you are asked to make basic calculations on the spped
of the new END Stumptown shoes in kilometers per hour along diifferent routes that I typically run.
My route names include abbreviations and nicknames for locations.
KasEl refers to passing through the intersection of Kaselehlie and Elenieng at AMCRES.
OAB is an abbreviation for "out-and-back," NBFS is "Nett Bridge Far Side."
Sant refers to the Spanish name for Kolonia: Santiago de la Ascension.
In my running logs Sant means passing Spanish wall.
_________ Calculate the sample standard deviation sx.
_________ Calculate the sample Coefficient of Variation.
_________ Determine the class width. Use five classes (bins or intervals).
Fill in the following table with the class upper limits in the first column,
the frequencies in the second column, and the relative frequencies in the third column
Bins (x)
Frequency f
RF p(x)
Sums:
Sketch a histogram of the relative frequency data.
__________________ What is the shape of the distribution?
__________________
On 01 January 2009, New Year's day, I ran an odd route. Every time I heard pots banging,
I ran to the noise running and juggling. I wound up running all over Kolonia.
The resulting run was very slow, only 5.84 kph.
Use the sample mean x and sample standard deviation sx above
to calculate the z-score for
5.84 kph.
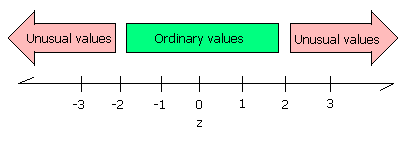
_________ Is the z-score for
5.84 kph an ordinary or extraordinary value?
__________________
On 07 April 2009 I ran in an older pair of Mizuno Wave Renegade IV running shoes.
I ran one way to the Nett river bridge at 11.46 kph.
Use the sample mean x and sample standard deviation sx above
to calculate the z-score for
11.46 kph.
_________ Is the z-score for
11.46 kph an ordinary or extraordinary value?
_________ Calculate the standard error of the sample mean x
_________ Find tcritical for a confidence level c of 95%
_________ Determine the margin of error E for the sample mean x.
Write out the 95% confidence interval for the population mean μ
p(_____________ < μ < ___________) = 0.95
_________
My average speed in the Mizuno Wave Renegade IV shoes is
9.05 kph.
Based on the confidence interval above,
is the mean speed in the newer, lighter END Stumptown shoes
different than the μ =
9.05 kph?
___________
Using END Stumptown speed data above and a population mean μ =
9.05 kph
determine the t-statistic.
___________
Using END Stumptown speed data above and a population mean μ =
9.05 kph
determine the p-value.
___________
Using END Stumptown speed data above and a population mean μ =
9.05 kph
determine the maximum confidence c interval for which the difference is statistically significant.
___________
Based on the hypothesis test above, at an alpha of 0.05, are the END Stumptown shoes
statistically significantly faster than the Mizuno Wave Renegade IV shoes?
Part II: Hypothesis Testing using the t-test
In part two you will run a paired data two sample hypothesis test on whether the END Stumptown shoes are associated with a
statistically significantly different speed from the Mizuno Wave Renegade IV shoes.
At the end of part one you ran a hypothesis test against a population mean speed of 9.05 kph.
The problem with that hypothesis test is that my speed varies with the length of the route.
By comparing my speed in the END shoes versus the speed in the Mizuno shoes on the same route, a more accurate
hypothesis test can be run. Use a paired t-test for two samples to determine whether the lighter
END Stumptown shoes are faster for me than the heavier Mizuno Wave Renegade 4 shoes.
Route
END
MZ WR 4
Airport OAB
10.53
8.47
Koahn-Sant
9.57
9.37
Lida OAB
9.50
8.81
LTLR
11.11
9.01
NBFS-KasEl Sant
9.34
8.83
Palipowe-KasEl-Lida
9.81
8.67
Santarch
10.30
9.61
_________ Calculate the sample mean
speed for the END Stumptown shoes using the above data.
_________ Calculate the sample mean
speed for the Mizuno Wave Renegade IV shoes using the above data.
_________ Are the sample means for the two samples mathematically different?
__________________
What is the p-value? Use the difference of means for paired data TTEST function
=TTEST(END-data;MZWR4-data;2;1) to determine the p-value for this two sample data.
__________________ Is the difference in the means statistically significant
at a risk of a type I error alpha α = 0.05?
__________________ Would we fail to rejectorreject a null hypothesis of no difference
in the sample means?
__________________ What is the maximum level of confidence we can have that the
difference is statistically significant?
Part III: Linear Regression (best fit or least squares line)
Data table
Route
Distance (km)
Speed (kph)
Santarch
4.06
9.63
Santarch
4.06
10.96
LTLR
4.76
11.11
Lida OAB
5.71
9.50
Genesis-Sant
6.75
8.66
Airport OAB
7.90
10.53
NBFS-KasEl Sant
9.15
9.34
Koahn-Sant
9.99
9.57
Palipowe KasEl OAB
10.44
8.44
Palipowe-KasEl-Lida
12.90
9.81
Koahn-airport
13.48
9.24
U airport
16.53
8.45
Runners tend to run at the fastest speed for which they can still finish the distance.
Thirty years of running have trained me to know how fast I can go for a given distance.
To go farther I have to run a little slower.
This last section of the final explores this relationship between the length of a run
in kilometers and the speed at which I run.
_________ Calculate the slope of the linear regression (best fit line).
_________ Calculate the y-intercept of the linear regression (best fit line).
_________ Is the relation between distance and speed positive, negative, or neutral?
_________ Calculate the linear correlation coefficient r for the data.
______________ Is the correlation none, weak/low, moderate, strong/high, or perfect?
______________ Determine the coefficient of determination.
______________ What percent in the variation in
the distance
"explains" the variation in
the speed?
_________ Use the slope and intercept to predict
the speed for an 8 kilometer run.
_________ Use the slope and intercept to determine
the distance I would be predicted to run at 9 kph.
_________ If I run zero kilometers, what speed does the regression predict?
-->
One intention of any course is that a student should be able to
learn and employ new concepts in the field even after the course is over.
In a linear regression analysis a correlation coefficient near
zero means no relation exists between the variables.
You can run a statistical test to determine whether the
correlation coefficient r is
statistically signigicantly different from zero.
If the difference of r from zero is statistically significant,
then you will have proved that a relationship exists.
If you fail to reject a null hypothesis of r equals zero,
then there is no evidence in the data that minutes of running and total steps are related.
To run the hypothesis test, you will calculate a
t-critical (tc), a t-statistic (t), and then a p-value
using the t-statistic and the TDIST function.
For this test:
The sample size n is the number of data pairs
t-critical: =TINV(α;n−2) where α = 0.05
p-value: =TDIST(ABS(t-statistic);n−2;2)
Note that n−2 is used in these formulas. This is the degrees
of freedom for a correlation hypothesis test.
_________ Determine the sample size n
by counting the number of data pairs.
_________ Determine t-critical using an alpha of α = 0.05
and n − 2 degrees of freedom.
_________
Determine the t-statistic using the formula noted above.
_________ Determine the p-value using the TDIST function,
remembering to use n − 2 for the degrees of freedom.
________ Is the correlation between
my distance and speed statistically significant?
Tables of Formulas and OpenOffice Calc functions
Basic Statistics
Statistic or Parameter
Symbol
Equations
OpenOffice
Square root
=SQRT(number)
sample size n
n
=COUNT(data)
sample mean
x
Σx/n
=AVERAGE(data)
Sample standard deviation
sx or s
=STDEV(data)
Sample Coefficient of Variation
CV
sx / x
=STDEV(data)/AVERAGE(data)
Formula to calculate a z value from an x value
z
=STANDARDIZE(x;x;sx)
Confidence interval statistics for a single sample
Statistic or Parameter
Symbol
Equations
OpenOffice
Sample size
n
n
=COUNT(data)
Degrees of freedom
df
n − 1
=COUNT(data)-1
Find a tcritical value from a confidence level c
tc
=TINV(1-c;df)
Standard error of a sample mean x
SE
=STDEV(data)/SQRT(n)
Standard error of a sample proportion p
SE
=SQRT(p*q/n)
Calculate a margin of error for the mean E using tcritical and the standard error SE.
E
=tc*SE
Calculate a confidence interval for a population mean μ from a sample mean
x and a margin of error E
x - E < μ < x + E
Calculate a confidence interval for a population proportion P from a sample proportion p and a margin of error E
p - E < P < p + E
Hypothesis testing for a sample mean versus a known population mean
Statistic or Parameter
Symbol
Equations
OpenOffice
Relationship between confidence level c and alpha α for two-tailed tests
1 − c = α
Calculate t-critical for a two-tailed test
tc
=TINV(α;df)
Calculate a t-statistic
t
=(x - μ)/(sx/SQRT(n))
Calculate a two-tailed p-value from a t-statistic
p-value
= TDIST(ABS(t);df;2)
Hypothesis testing for paired data samples
Statistic or Parameter
Symbol
Equations
OpenOffice
Calculate a p-value for the difference of the means from two samples of paired data
=TTEST(data_range_x;data_range_y;2;1)
Hypothesis testing and confidence intervals for two independent samples
Statistic or Parameter
Symbol
Equations
OpenOffice
Degrees of freedom (approx.)
df
[smaller sample n] − 1
=COUNT(smaller sample)-1
Calculate t-critical for a two-tailed test
tc
=TINV(α;df)
Calculate the standard error SE for two independent samples
SE
=sqrt((sx^2/nx)+(sy^2/ny))
Calculate a margin of error E for two independent samples using tcritical and the standard error SE.
E
=tc*SE
Calculate the difference between two sample means
xd
x − y
=average(data set x)-average(data set y)
Calculate a confidence interval for a population mean difference μd
from a sample mean difference xd and a margin of error E
xd − E < μd <
xd + E
Calculate a p-value for the difference of the means for two independent samples (data unpaired, independent) where the population standard deviations are unknown